|
Страница 2 из 2
4. Метод експерименту
Експеримент відноситься до найбільш своєрідних і важко засвоюваних методів збирання соціологічної інформації. В соціології експеримент - це спосіб одержання інформації про кількісні та якісні зміни показників діяльності і поведінки соціального об'єкта в результаті дії на нього деяких факторів, які піддаються контролю та управлінню. Загальна логіка експерименту полягає в тому, щоб за допомогою відбору певної експериментальної групи (або груп) та введенні її в надзвичайну експериментальну ситуацію (під впливом певного фактора) прослідити напрямок, величину, стійкість тих характеристик, які цікавлять дослідника.
Експерименти відрізняються як за характером експериментальної ситуації, так і за логічною структурою доведення гіпотез.
За характером експериментальної ситуації експерименти поділяються на польові та лабораторні. В польовому експерименті об'єкт (група) перебуває в природних умовах свого функціонування (наприклад, студентська група на практичних заняттях). При цьому члени групи можуть бути повідомлені або не повідомлені відносно своєї участі в експерименті.
При лабораторному експерименті експериментальна ситуація, а нерідко і самі експериментальні групи формуються штучно. Тому члени групи, як правило, інформуються про участь в експерименті.
Як в польовому, так і в лабораторному експерименті в якості додаткових методів збору інформації про хід експеримента можуть практикуватись опитування та спостереження. Їхні результати надають досліднику право вирішувати питання про те чи втручатись в процес протікання експеримента чи спостерігати за ним без втручання до повного закінчення.
За логічною структурою доведення гіпотез виділяють лінійний і паралельний експерименти. Лінійний експеримент відрізняється тим, що аналізу піддається одна і таж група, яка виступає і як контрольна (її первинний стан), і як експериментальна (її стан після зміни однієї або декількох характеристик). Тобто ще до початку експерименту чітко фіксуються всі контрольні, факторні і нейтральні характеристики об'єкта. Після цього змінюються факторні характеристики групи (або умови його функціонування) і через певний час знову заміряється стан об'єкта за його контрольними ознаками. Як приклад лінійного експерименту можна розглядати такий процес, коли одна і таж студентська група за задумом експериментатора працює один семестр в тих же умовах, що і інші, а наступний семестр для неї створюються особливі умови (всіх забезпечують необхідною навчальною літературою, заняття проводяться тільки в обладнаних аудиторіях, лекції читають найбільш кваліфіковані викладачі і т. д.). Після закінчення експерименту порівнюють результативність двох семестрів і роблять висновки.
При паралельному експерименті задіяні дві групи: контрольна та експериментальна. Склад цих груп повинен бути ідентичним за всіма контрольними, а також нейтральними характеристиками, які можуть впливати на результативність експерименту (в першу чергу це соціально-демографічні ознаки). Характеристики контрольної групи залишаються постійними протягом всього періоду експерименту, а експериментальні - змінюються. За результатами експерименту контрольні характеристики обох груп порівнюються, після чого робиться висновок про причини та розміри тих змін, які мають місце в контрольній групі. Прикладом паралельного експерименту може бути ситуація, коли відбирають дві групи студентів однієї спеціальності і одного року навчання. Для однієї групи створюють якісь особливі умови у навчанні, інша ж перебуває в тих же умовах, що і більшість студентських груп. Протягом семестру за обома групами ведеться спостереження, а після закінчення сесії робляться висновки.
Треба сказати, що для успішного проведення експерименту велику роль видіграє правильний відбір його учасників. В прикладній соціології виділяють такі методи відбору експериментальних груп, як метод попарного відбору, метод структурної ідентифікації та метод випадкового відбору.
Метод попарного відбору застосовується переважно в паралельному експерименті. Суть його полягає в тому, що із генеральної сукупності відбираються дві групи таким чином, щоб вони були ідентичними за нейтральними і контрольними, але відрізнялись за факторними характеристиками. Після цього для двох груп створюються однакові умови і через деякий час заміряється ефект експеримента шляхом фіксації та порівняння параметрів контрольних ознак у двох групах.
В лінійному і паралельному експерименті можна застосовувати метод структурної ідентифікації. В даному випадку при лінійному експерименті група вибирається таким чином, щоб вона являла собою мікромодель генеральної сукупності відповідно до нейтральних і контрольних характеристик. Такий відбір може бути здійснений за принципом квотної вибірки. В свою чергу, при паралельному експерименті за тими ж самими характеристиками вирівнюються структури експериментальної і контрольної груп. Наприклад, ми маємо дві групи в 20 і 35 чоловік. Відомо, що в першій експериментальній групі середню спеціальну освіту мають 50% членів груп (10 чоловік) і решта 50% (10 чоловік) є випускниками гімназії. В другій (контрольній групі) їх доля дорівнює відповідно 42,2% (15 чоловік) та 57,8% (20 чоловік). Припустимо, що з метою створення експериментальної ситуації, бажано за характеристикою "рівень освіти" структуру контрольної групи привести у відповідність до структури експериментальної. Тоді за допомогою арифметичних прийомів ми знаходимо, що контрольна група повинна складати 30 осіб: 15 чоловік (50%) - тих, хто має спеціальну середню освіту і 15 чоловік (50% ) - випускників гімназії.
Метод випадкового відбору є ідентичним до вище охарактеризованих методів ймовірної вибірки із заданим наперед об'ємом. Як правило, його застосовують у польових експериментах, коли чисельність експериментальної групи досить велика (у кілька сот чоловік).
Підготовка та проведення експеримента передбачає послідовне вирішення ряду питань:
1) визначення мети експеримента;
2) вибір об'єкта (об'єктів), який (які) використовуються в якості експериментальної (а також контрольної) групи (груп);
3) визначення предмета експеримента;
4) визначення контрольних, факторних та нейтральних ознак;
5) визначення умов експеримента і створення експериментальної ситуації;
6) формулювання гіпотез і визначення завдань;
7) вибір індикаторів та способів контролю за протіканням експерименту;
8) визначення методів фіксації результатів;
9) перевірку ефективності експеримента.
Логіка експеримента завжди підпорядкована пошуку причин, характеру змін у тому соціальному явищі, яке цікавить дослідника. Головною умовою їх знаходження є зміна стану експериментальної групи в разі дії певних факторів. Так, група має стан А. В ході експеримента вводиться Ф (зміни в одній із звичайних умов її функціонування, або ж зміни якихось власних її характеристик). В результаті група набуває стану А1. Тоді завданням дослідника є визначення рівня впливу фактора Ф на зміни у групі, а також розміру цих змін.
Розглянемо логічну модель проведення лінійного і паралельного видів експерименту.
Лінійний експеримент. Схематично процес змін у стані об'єкта в лінійному експерименті можна зобразити так:

Під новим станом об'єкта розуміється зміна його однієї чи декількох характеристик. В зв'язку із цим, фактор, що діє на об'єкт, а також ефективність його дії, можуть бути визначені за допомогою такої схематичної моделі:

В даній моделі: "а", "б", "в", "г", "д" - різні характеристики експериментальної групи (стать, вік, сімейний стан, соціальне походження, етнічна належність і т. д.)
Наведена схема розшифровується так: під впливом характеристик "а", "б", "в" похідного стану (А) експериментального об'єкта маємо його результуючий стан (А1) з характеристиками "г", "д". Після зміни характеристики "в" результуючий стан змінюється за характеристикою "д". Відповідно робимо висновок про те, що зміна характеристики "д" на "д1" викликана зміною характеристики "в" на "в1".
Логічна модель паралельного експеримента має два різновиди: модель по методу однієї схожості і модель однієї різниці.
Модель по методу однієї схожості має таку логічну схему за умовами порівняння експериментальної групи А і контрольної групи Б:

Наведена модель має таку розшифровку: нехай якась експериментальна група (А) з характеристиками "а", "б" та "в" в певному стані має властивості "г" і "д", а контрольна група (Б) з характеристиками "е", "ж" та "в" в тому ж стані має властивості "з" та "д". В цьому зв'язку доцільно зробити висновок, що єдиною причиною властивості "д" є характеристика "в", так як тільки вона присутня серед характеристик обох об'єктів.
В даному випадку метод подібності можна зобразити за допомогою такої форми. Припустимо, що є дві групи з однаковим рівнем освіти, але різною суспільною активністю. Заняття в обох групах проводяться за активним методом. При цьому, хоча середній рівень відвідування занять відрізняється по групах, середній рівень знань в обох групах однаковий. В даному випадку можна зробити висновок, що середній рівень знань у групах є похідною від методу навчання.
Модель з методу однієї різниці має таку логічну схему:

За допомогою того ж прикладу, наведена модель буде мати слідуючу інтерпретацію. Є дві групи із однаковим рівнем освіти та суспільної активності, однак в одній групі практикуються пасивні методи навчання, в іншій - активні. При однаковому рівні відвідування практичних занять в другій групі активність студентів вище, ніж у першій. В цьому зв'язку можна зробити припущення, що причиною високої активності на практичних заняттях у другій групі є застосування більш активних методів навчання.
Необхідно пам'ятати, що практика експерименту в соціології пов'язана з рядом труднощів, що не дає можливості досягти чистоти природознавчого експеримента. Пояснюється це тим, що в соціологічному експерименті неможливо усунути вплив відносин, які існують за межами об'єкта, що досліджується. Також не можливо здійснити в тій же самій формі його хід і результати. Експеримент в соціології торкається безпосередньо конкретної людини, що висуває також і проблеми етичного плану і тим самим звужує границі застосування експеримента і вимагає від дослідника підвищеної відповідальності.
5. Методи обробки та статистичного групування одержаних соціологічних даних
Перш за все, для того, щоб зібрані дані можна було обробити та узагальнити, заповнений інструментарій має пройти стадію попередньої підготовки до обробки. Перший етап такої підготовки - перевірка методичного інструментарію на точність, повноту та якість заповнення.
Перевірка на точність заповнення полягає у виявленні правильної відповіді на кожне питання та у виправленні помилок у випадках їх наявності. Наприклад, у питанні: "чи знаєте Ви про основні планові заходи щодо відпочинку студентів, які розробив студентський профком на поточний рік?" - може бути обведеною відповідь "так, знаю". В той же час наступне відкрите питання: "Якщо знаєте, назвіть будь-ласка їх" - залишається без відповіді. В даному випадку варіант відповіді "так, знаю" необхідно закреслити і відмітити позицію "немає відповіді".
Перевірка анкети, бланків інтерв'ю на повноту заповнення передбачає вибраковку тих із них, у яких відсутні відповіді на якісь питання відносно соціально-демографічних характеристик респондента (стать, вік, сімейний стан, освіта), то вона також підлягає вибраковці.
Перевірка анкет на якість заповнення полягає в уважному перегляді їх на предмет ясності, чіткості та зрозумілості відповідей, обводки кодів. Справа в тім, що незрозумілий (нечіткий, неакуратний) почерк виключає можливість точної і однозначної інтерпретації відповідей, робить анкету, бланк-інтерв'ю неприродними для обробки.
Всі анкети, бланки-інтерв'ю і т. і., в яких мають місце перелічені вище недоліки виключаються із подальшого процесу обробки. Ті ж документи, що залишились, нумеруються і об'єднуються за ознаками належності до одного і того ж респондента. Слідуючий етап підготовки методичних документів до обробки полягає у кодуванні інформації.
Процедура кодування інформації являє собою допоміжний процес формалізації відповідей на питання, а також ряд інших моментів, пов'язаних із процедурою обробки та аналіза інформації.
Процедура кодування полязає в присвоєнні кожному варіанту відповіді умовного числа, яке називається кодом. Відповідно, вся інформація в анкеті чи бланку-інтерв'ю ніби-то "перетворюється" в упорядковану систему чисел. Коди мають бути безперервними, що означає: ні один код не може бути "загубленим". Також коди повинні бути строго упорядкованими, тобто переміна їхніх місць не допускається. Якщо ці вимоги не дотримуються, то вся структура інформації порушиться.
В залежності від того, який вид програми передбачається для обробки інформації на комп'ютері, відповіді можуть бути закодованими двома способами: або суцільною нумерацією всіх позицій (так звана порядкова система кодування), або нумерацією відповідей у кожному питанні автономно (позиційна система кодування). Порядкова (лінійна) форма відповідей на питання 15: "Які фактори стимулюють Ваше навчання у вузі?" - може бути представлена у такому вигляді:
|
Порядковий код
|
Варіанти відповідей
|
|
078
|
Бажання отримати знання
|
|
079
|
Необхідність мати диплом
|
|
080
|
Якщо стільки часу затрачено на навчання, то треба довести діло до кінця
|
Позиційна система кодування інформації виглядатиме так:
|
Варіанти відповідей
|
Позиційний код
|
|
Бажання отримати знання
|
1
|
|
Необхідність мати диплом
|
2
|
|
Якщо стільки часу затрачено на навчання, то треба довести діло до кінця
|
3
|
Як видно із прикладу, порядкові коди розташовуються, як правило, зліва, а позиційні - справа (щоб не переплутати з номером питання). Перед питанням стоїть номер 15, з чого робиться висновок, що в анкеті йому передували 14 питань і перша позиція наведеного питання закодована числом 078. Відповідно перша позиція наступного питання буде зазначена кодом 082.
Кодування інформації процес відповідальний. Тому є науково розроблені норми скільки кодувальників треба залучати в тому чи іншому випадку. Розраховується це за формулою:
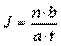
Де J - кількість кодувальників;
n - об'єм вибіркової сукупності, а значить і кількість анкет;
b - кількість питань у анкеті;
a - кількість питань, які може закодувати один кодувальник за день (500 питань);
t - час, за який треба виконати роботу.
Якщо у нас є 2000 анкет, в кожній анкеті 40 питань, а процес кодування необхідно завершити за десять днів, то підставивши дані у формулу ми без зайвих зусиль визначимо скільки кодувальників треба залучити до роботи
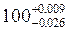
Після завершення процесу кодування первинної соціологічної інформації, приступають до її обробки. Ще на стадії розробки програми вирішується питання про те як буде оброблятись інформація - вручну, чи за допомогою комп'ютера. Ручна обробка, як правило, застосовується тоді, коли дослідник має справу з невеликою кількістю анкет (декілька десятків). Якщо анкета невелика, то це число може бути збільшене до 200-250.
Для обробки даних на комп'ютері складається програма. Цю частину роботи виконують спеціалісти. Результати обробки оформляються у вигляді Табуляграми. Дані в табуляграмі фіксуються, як правило, у формі, яка передбачена програмою обробки для відповідного типу комп'ютера.
Розглянемо логіку "прочитання" записів в табуляграмах на прикладах двох питань. Питання 11. "Як Ви відноситесь до необхідності систематичної роботи, направленої на поглиблення своїх знань?" (варіанти відповідей: 1 - вважаю це корисною і необхідною справою; 2 - вважаю в цілому це справою корисною, але для себе необов'язковою; 3 - не бачу користі і необхідності для себе у поглибленні знань; 4 - затрудняюсь відповісти). Питання 32. "Як Ви навчаєтесь?" (варіанти відповідей: 1 - маю тільки відмінні оцінки; 2 - є відмінні і добрі оцінки; 3 - вчусь тільки на трійки).
Табуляграма, яка відображає поєднання відповідей на обидва питання (так зване попарне розміщення даних), буде мати слідуючий вигляд (всього опитано 2000 респондентів):
|
Номер питання
Номер позиції
|
32
1
|
32
2
|
32
3
|
0
0
|
|
11
|
686
|
354
|
49
|
1089
|
|
1
|
87,3%
|
42,2%
|
13,0%
|
54,5%
|
|
11
|
77
|
256
|
159
|
492
|
|
2
|
9,8%
|
30,5%
|
42,3%
|
24,6%
|
|
11
|
0
|
52
|
59
|
111
|
|
3
|
0,0%
|
6,3%
|
15,7%
|
5,5%
|
|
11
|
23
|
176
|
109
|
308
|
|
4
|
2,9%
|
21,0%
|
29,0%
|
15,4%
|
|
0
|
786
|
838
|
376
|
2000
|
|
0
|
39,3%
|
41,9%
|
18,8%
|
100,0%
|
Зазначення числових рядів в табуляграмі: в першому ряді вказаний номер питання (32), що визначає рівень успішності; в другому ряді записані номери позицій питання 32; в третьому ряді вказується абсолютне число опитаних, які вибрали в якості відповіді першу позицію питання 11; в четвертому ряді даються ті ж відомості, але виражені у відсотках. Подальші рядки читаються аналогічно. В останній колонці (код 0) вказані абсолютні величини і відсотки від числа опитаних, що відмітили відповідно ту чи іншу позицію питання 11. В останньому рядку табуляграми (код 0) вказані абсолютна величина та частка у відсотках опитаних, які відмітили відповіді позицій питання 32. Наведений приклад - не єдиний вид запису узагальненої соціологічної інформації. Відображення соціологічних даних має ряд інших, більш складних математичних і геометричних форм. Їх вибір залежить від глибини аналізу соціального явища, що вивчається
Слід пам'ятати, що характер відображення соціологічних даних визначається насамперед формою узагальнення первинної інформації. Сама простіша його форма - групування. Підбиваючи підсумок відповідей на позиції питань анкети з урахуванням вибраного признака, дослідник здійснює не що інше, як просте групування тих, хто відповів в залежності від їх соціально-демографічних ознак, установок, інформованості, оцінок і т. д. Виділені таким чином однорідні за складом групи значно легше співвідносити, порівнявати, аналізувати.
Вибір признака групування - не довільна процедура. В залежності від шкали виміру відповідно з якою одержані відповіді на питання, групування соціологічної інформації може являти собою:
- зарахування респондентів до номінальних груп (групування опитаних за ознаками статі, національності, місця проживання і т. д.); - упорядкування інформації у ранжированому ряді, наприклад за характером праці (ті, хто займаються ручною працею, ті, хто має справу з механізмами, працівники, що виконують розумову роботу);
- групування за кількісними ознаками, в результаті чого групи респондентів характеризуються числовою величиною і тому їх можна кількісно порівнювати між собою (наприкладі групування за віковими інтервалами: 18-25 років, 26-30 років, 31-40 років, 41-50 років, 50 років і старше).
В результаті групування виділяється не одна, а декілька груп. При цьому кожній виділеній групі відповідає деяке число, що визначає її кількісний склад. Такий ряд чисел, що одержується в результаті групування, називають рядом розподілення. Ряди розподілення, що відображають результат групування респондентів за якісними ознаками, називаються атрибутивними, а ті, що за кількісними ознаками - варіаційні. Відповідно до характеру кількісних ознак варіаційні ряди поділяються на дискретні і безперервні. Останні, як правило, мають інтервальний характер. Це означає, що та чи інша група респондентів характеризується за кількісною ознакою не одним числом, а числовим інтервалом, наприклад віковим інтервалом: 20-24 роки, 25-30 років і т. д. Вибір інтервалів в значній мірі залежить від дослідника і здійснюється відповідно до завдань дослідника. Так, вивчення питання адаптації молодих спеціалістів на виробництві передбачає у показнику "стаж роботи" досить вузькі інтервали (1-3 місяці, 4-6 місяців, 7-9 місяців, 10 місяців-1 рік), а от вивчення відмінностей у рівні професійної майстерності - більш широкі (1-3 роки, 4-5 років, 6-10 років).
Ряди розподілення поряд із числовою мають і текстову характеристику. Таке відображення даних паралельно з супроводжуючим пояснювальним текстом здійснюється за допомогою таблиць. Побудова таблиці відбувається згідно з установленими правилами. В назві повинен бути відображений основний зміст таблиці (коло питань, що розглядається, географічні кордони статистичної сукупності, час, одиниці виміру).
Таблиці можуть бути прості і комбінаційні.
Прості таблиці являють собою перелік, список окремих одиниць сукупності з кількісною (або якісною характеристикою кожної із них окремо). Найбільш проста - перелікова таблиця складається на основі розподілення за однією ознакою (див. Таблицю 1).
Таблиця 1 Розподіл студентів 2-го курсу медичного факультету СумДУ за характером середньої освіти.
|
Характер освіти
|
Середня Спеціальна (медучилище)
|
Гімназична (ліцейні класи)
|
Середня школаIII-IV рівнів
|
Загальна кількість студентів
|
|
Всього студентів
|
20
|
20
|
40
|
100
|
|
Частка у процентах
|
20%
|
20%
|
40%
|
100%
|
Таблиці, які відображають ряди розподілення за двома і більше ознаками, називаються комбінаційними (див. Таблицю 2)
Таблиця 2 Розподіл студентів за віком, що були прийняті на 1-й курс заочного факультету СумДУ в 2000 році.
Така таблиця являє собою дещо більше, ніж простий перелік даних, вона є способом і, разом з тим, результатом певної організації даних. Добре сконструйована таблиця надає можливість досліднику більш чітко уявити та описати зміст і сутність соціального явища, що вивчається.
Таким чином, Метод групування та подання матеріалу у вигляді статистичних таблиць вже створюють певні можливості для вивчення соціологічних даних. З іншого боку, подібні методи є необхідним засобом для подальшого аналізу та застосування більш досконалих статистичних методів.
Частотний розподіл може зображуватись також у вигляді діаграм та графіків. Основною перевагою графічного зображення є його наочність. Графічна інтерпретація емпіричних залежностей заснована на знанні технічних правил побудови рядів, типів та властивостей теоретичних розподілів. Найпоширенішими графіками, що практикуються у соціології, є гістограма, полігон та комулята розподілення.
Гістограма розподілу шлюбного віку подружніх пар, які розлучаються
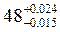
Для побудови полігона величина признака відкладається на вісі абсцис, а частота на вісі ординат. З точок, які відповідають значенням признака, будуються перпендикуляри, що дорівнюють по висоті частотам. Вершини перпендикулярів сполучаються прямими лініями.
Для інтервального ряда ординати, пропорційні частоті (або відносній частоті) інтервала, будуються перпендикулярно вісі абсцис в точці, що відповідає середині даного інтервала.
Приведені дані розподілу випускників СумДУ по категоріям бакалавр, спеціаліст, магістр дають можливість побудувати полігон розподілу
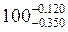
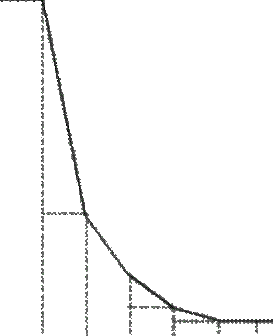
Для графічного зображення варіаційних рядів застосовують також кумулятивні криві. При побудові кумуляти, як і гістограми, на вісі абсцис відкладають границі інтервалів, а на вісі ординат - накопичені частоти (або відносні частоти), які відповідають верхнім межам інтервалів. Таким чином, кумулята являє собою ламану лінію, яка дає можливість швидко визначити процент осіб, які знаходяться нижче або вище заданої величини признака.
Кумулята розподілу шлюбного віку подружніх пар, які розлучаються
Поряд із графічним, більш глибоке узагальнення первинної соціологічної інформації передбачає визначення спеціальних статистичних величин (середньої арифметичної та дисперсії).
Середня арифметична - це інтегральна, узагальнена величина, яка дає можливість порівнювати між собою не тільки групи одного ряду розподілення, але й самі ряди розподілення в тих випадках, коли вони будуються за ідентичними ознаками. Загальна формула для її визначення має такий вигляд

Де 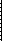 - числове значення варіацій признака, i - число варіацій. Знак - числове значення варіацій признака, i - число варіацій. Знак 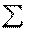 Означає суму. Розглянемо приклад визначення середньої арифметичної. Є три величини, які характеризують відвідування студентами практичних занять з соціології на початку семестру: перше заняття відвідали 30 студентів, друге - 28 і третє - 32. Означає суму. Розглянемо приклад визначення середньої арифметичної. Є три величини, які характеризують відвідування студентами практичних занять з соціології на початку семестру: перше заняття відвідали 30 студентів, друге - 28 і третє - 32.
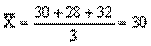
Така (проста) середня арифметична визначається в тих випадках, коли групування інформації здійснюється за признаком, який не має варіацій і, відповідно, власних числових значень. Але таке бувае досить рідко, адже більшість при знаків, для групувань, за якими визначають середнє значення є кількісними. Тому в соціологічному дослідженні, як правио, визначається так звана зважена середня арифметична.
Уявимо, що в результаті опитування 200 респондентів такі дали за ознаками "вік" і "кількість відвідувань обласного театру" (див. Таблиці 3 та 4)
Таблиця 3 Таблиця 4 Розподіл респондентів Розподіл респондентів за за кількістю відвідувань віковими групами ними обласного театру
|
Кількість відвідувань театру
|
Абсолютне число респондентів
|
Вік (років - х)
|
Абсолютне число респондентів
|
Середнє інтегральне значення для віку (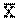 ) )
|
|
Один раз на місяць
|
100
|
41-50
|
40
|
45,5
|
|
Два рази на місяць
|
50
|
31-40
|
120
|
35,5
|
|
Три рази на місяць
|
40
|
26-30
|
30
|
28,0
|
|
Не відвідували ні разу
|
10
|
20-25
|
10
|
22,5
|
В таблицях наведені дані за двома показниками. Визначення середньої арифметичної для даних у кожній таблиці має свої особливості. Признак "кількість відвідувань обласного театру" має позиції, які виражені однозначними числовими величинами (один раз на місяць, два рази на місяць і т. д.). За ознакою "віку" вони розподілені в інтервалах (наприклад, від 41 до 50 років). Зважені середні арифметичні для значення признака визначаються за однозначними величинами, тому для інтервалів заздалегідь необхідно визначити середнє значення кожної позиції показника "вік" (дані у третьому стовпчику таблиці 5). Усереднення інтервала відбувається шляхом визначення простої середньої для кожної градації віку (наприклад 41-50, або 31-40), тобто сума крайніх значень інтервала ділиться на число цих значень (у нашому випадку на 2).
Наше завдання - виходячи із даних таблиці, визначити середню кількість відвідувань театру та середній вік у розрахунку на одного респондента. В таких випадках звішену середню арифметичну визначаємо за формулою:
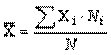
Де - числове значення 1 - ї позиції признака, 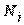 - число респондентів, виділених за першою позицією признака, - число респондентів, виділених за першою позицією признака, 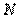 - загальне число респондентів, які підлягають групуванню ( - загальне число респондентів, які підлягають групуванню (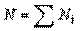 ). ).
Підставивши у формулу значення із таблиці 4 за ознакою "кількість відвідувань обласного театру" одержимо:
 рази рази
Це означає, що на кожного опитаного в середньому припадає 1,6 відвідувань.
Визначення середньої для ознаки "вік" здійснюється за допомогою тієї ж формули, з використанням середніх значень по кожному інтервалу.
Таким чином, середній вік опитаних буде:
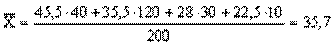 роки. роки.
Недоліки середньої арифметичної як характеристики опитуваних за деякою ознакою полягають у тому, що вона може таїти в собі різну ступінь "розсіювання" значень, і тим самим якісне порівняння різних груп за даними характеристиками ускладнюється.
В таких випадках, для того щоб визначити ступінь рівномірності або нерівномірності тієї чи іншої характеристики опитуваних, застосовується формула розрахування ступеню розсіювання значень признака, якій називають дисперсією і позначають буквою 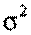 (сігма в квадраті): (сігма в квадраті):
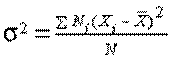 роки. роки.
Значення дисперсії простіше визначити, якщо в таблицю заздалегідь внести окремі елементи та їх розрахунки (див. Таблицю 5).
Таблиця 5
|
№п/п
|
Відвідування театру в 1-й групі Х1
|
Відхилення від середньої Х1-Хср1
|
Величина квадратичного відхилення (Х1-Хср1)2
|
Відвідування в 2-й групі Х2
|
Відхилення від середньої Х2-Хср2
|
Величина квадратичного відхилення (Х2-Хср2)2
|
|
1
|
18
|
-1
|
1
|
15
|
-4
|
16
|
|
2
|
20
|
+1
|
1
|
23
|
+4
|
16
|
|
3
|
20
|
+1
|
1
|
10
|
-9
|
81
|
|
4
|
18
|
-1
|
1
|
28
|
+9
|
81
|
Дана таблиця складена на основі такого припущення. Є дві групи респондентів: в одній - 20, в іншій - 30 чоловік. Протягом 4-х днів в першій групі відвідали бібліотеку (відповідно) 18, 20, 20, 18 чоловік; в другій групі 15, 23, 10, 28 - чоловік.
Враховуючи, що наш признак "відвідування" має однозначну інтерпретацію в кожному із чотирьох випадків, дисперсію можна визначити аналогічно простій середній.
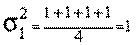 
Більшому значенню дисперсії відповідає і більше розсіювання признака (в нашому випадку - нерівномірність відвідування бібліотеки).
Більш поглиблений вид математичного аналізу характеристик явищ, що вивчаються проявляється у виявленні їх взаємодії та тенденцій до змін. Здійснюється це за допомогою порівнянь і співставлення рядів розподілення, побудованих на основі групувань за різними ознаками. Для рішення подібних задач існують спеціальні коефіцієнти кореляції.
Кореляція означає наявність статистичного зв'язку при знаків. Із розрахунком одного із такий коефіцієнтів - коефіцієнта рангової кореляції 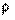 (ро) - варто познайомитися, так як він легко піддається вирахуванню "вручну" (тобто без комп'ютера), а застосування його є досить ефективним при аналізі розподілу соціологічної інформації, одержаної за допомогою рангової шкали. Формула коефіцієнта рангової кореляції має такий вигляд: (ро) - варто познайомитися, так як він легко піддається вирахуванню "вручну" (тобто без комп'ютера), а застосування його є досить ефективним при аналізі розподілу соціологічної інформації, одержаної за допомогою рангової шкали. Формула коефіцієнта рангової кореляції має такий вигляд:
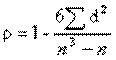
Де 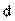 - різність рангів; - різність рангів;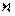 - загальна кількість рангів, тобто варіантів відповідей; - загальна кількість рангів, тобто варіантів відповідей;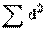 - сума квадратів різниці рангів. Коефіцієнт рангової кореляції змінює свою величину від -1 до +1. - сума квадратів різниці рангів. Коефіцієнт рангової кореляції змінює свою величину від -1 до +1.
Фактично коефіцієнт рангової кореляції виявляє ступінь ідентичності розподілу відповідей двох груп, що порівнюються при відповіді на одне і те ж питання, позиції якого є показниками рангової шкали. При  Порядок розподілу відповідей двох груп, що порівнюються прямо протилежний, а при він повністю співпадає. Застосування коефіцієнта рангової кореляції є ефективним також для порівняння даних анкетного опитування. Порядок розподілу відповідей двох груп, що порівнюються прямо протилежний, а при він повністю співпадає. Застосування коефіцієнта рангової кореляції є ефективним також для порівняння даних анкетного опитування.
Розглянемо процедуру розрахунку коефіцієнта рангової кореляції, для чого проран жируємо за двома групами питання: "За яких джерел Ви частіше за все отримуєте необхідну наукову інформацію?" (див Таблицю 6).
Ранжирування відповідей побудуємо так, щоб максимальна кількість тих, хто звертається до того, чи іншого джерела була зазначена числом 1, менш значима - числом 2 і так дальше до 8 в міру зменшення кількості. Результати покажемо в таблиці 6.
Число позицій (або рангів) дорівнює: n=8. відповідно до одержаних значень маємо:
Таблиця 6
Розподіл відповідей респондентів за ознаками використання ними різних джерел одержання наукової інформації
|
№п/п
|
Джерела інформації
|
Дані по 1-й групі
|
Ранги відповідей по 1-й групі (Х1)
|
Дані по 2-й групі
|
Ранги відповідей по 2-й групі (Х2)
|
Різниця рангів d=Х1-Х2
|
|
1
|
Лекції
|
76,9
|
3
|
82,4
|
2
|
1
|
|
2
|
Практичні заняття
|
91,8
|
2
|
81,1
|
3
|
-1
|
|
3
|
Наукові видання
|
97,9
|
1
|
98,2
|
1
|
0
|
|
4
|
Науково-практичні конференції
|
46,2
|
6
|
60,3
|
4
|
2
|
|
5
|
Між особисте спілкування з колегами
|
55,6
|
5
|
39,5
|
8
|
-3
|
|
6
|
Газети
|
32,0
|
8
|
42,7
|
7
|
1
|
|
7
|
Телебачення
|
72,3
|
4
|
50,1
|
6
|
-2
|
|
8
|
Інтернет
|
36,5
|
7
|
52,4
|
5
|
2
|
Відповідно із визначеним значенням коефіцієнта можна зробити висновок, що характер звертання до джерел наукової інформації в цілому подібний в обох групах. Наведених методів узагальнення та відображення соціологічних даних в принципі достатньо для того, щоб вирішити проблеми, які виникають в процесі соціологічних досліджень на рівні підприємство, район, місто.
В тих же випадках, коли необхідно вирішувати якусь специфічну проблему, яка вимагає застосування методів багатомірного аналізу, доцільно звернутись за допомогою до спеціалістів за математичною статистикою і програмування.
<< Начало < Предыдущая 1 2 Следующая > Последняя >>
|






